
Screaming Frog: Crawl-Konfiguration
In diesem Guide leite ich dich durch die wichtigsten Einstellungen und Konfigurationen des Screaming Frogs. Natürlich funktioniert der Screamig Frog auch out of the box, doch eins ist ganz wichtig:
Du solltest nicht irgendwie crawlen, sondern mit gezielten Fragen und Hypothesen, eingebettet in eine SEO Strategie.
Abgeleitet davon ergibt sich für dich, wie du den Screaming Frog für deine Bedürfnisse konfigurieren solltest.
Was du hier lernst:
Dies ist keine abschließende Anleitung für die Crawl-Konfiguration, sondern eine Übersicht über die wichtigsten Möglichkeiten.
Wenn du eine tiefergreifende Erklärung der Konfigurationsmöglichkeiten suchst, empfehle ich dir meinen Online Kurs “Screaming Frog für Einsteiger:innen”.
Gibt es die eine perfekte Konfiguration?
Nein. Jede Webseite ist anders, jedes Projekt hat ein individuelles Ziel. Daher gibt es hier keine Config-File zum Download. Stattdessen erkläre ich die wichtigsten Einstellungen, sodass du dir diese Config-Datei selbst erstellen kannst.
Der Unterschied zwischen Einstellungen und Konfiguration
Es gibt zwei Bereiche, in denen du Einstellungen vornehmen kannst: Einstellungen und Konfiguration. Was ist der Unterschied?
Einstellungen
Hier kannst du alle Einstellungen vornehmen, die den Crawler als ganzes betreffen. Du findest hier unter anderem Einstellungen zu:
- Lizenz
- Erscheinungsbild
- Sprache
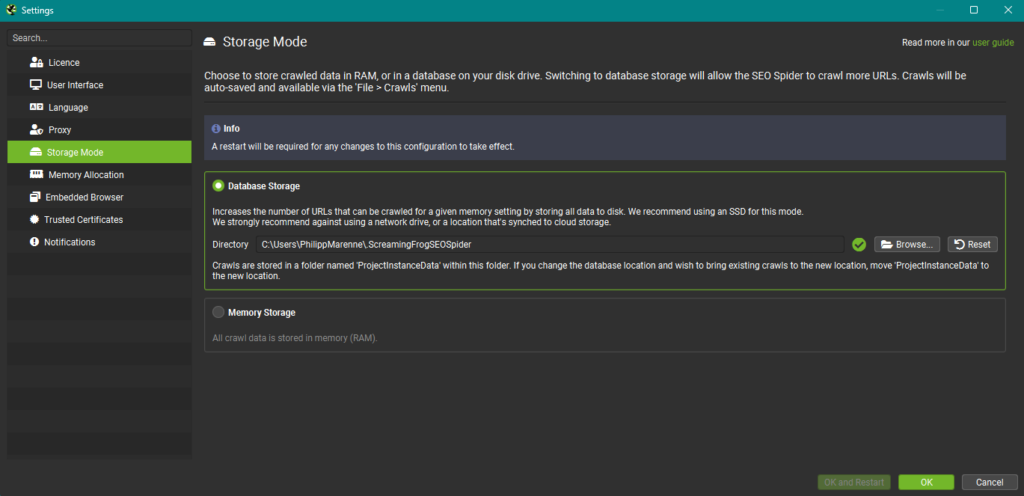
- Storage Mode
- Memory Allocation
Wichtig: Diese Einstellungen sind permanent, es genügt also, wenn du dich hier einmal einrichtest.
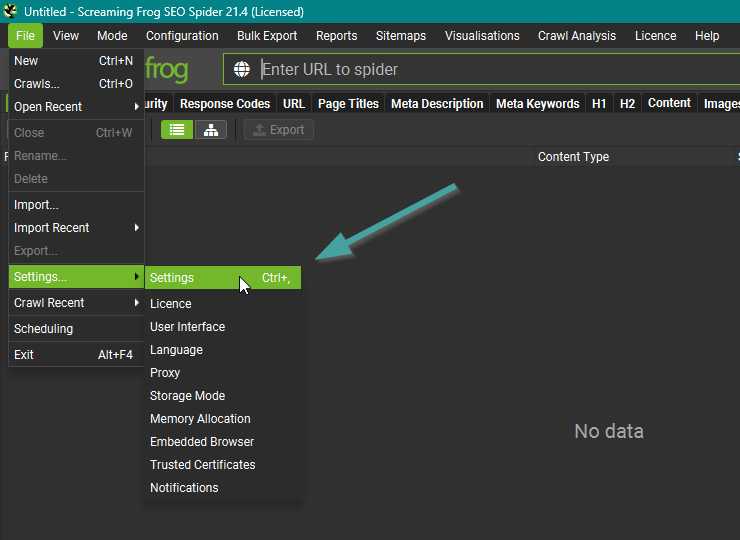
Konfiguration
Hier kannst du konfigurieren, wie sich der Crawler beim Crawlen selbst verhalten soll. Die Konfigurationsmöglichkeiten sind sehr umfassend, wir gehen im weiteren Verlauf des Guides auf vieles im Detail ein.
Wichtig: Die Konfiguration ist nicht permanent, das heißt, dass sie sich beim Schließen des Screaming Frogs zurücksetzt.
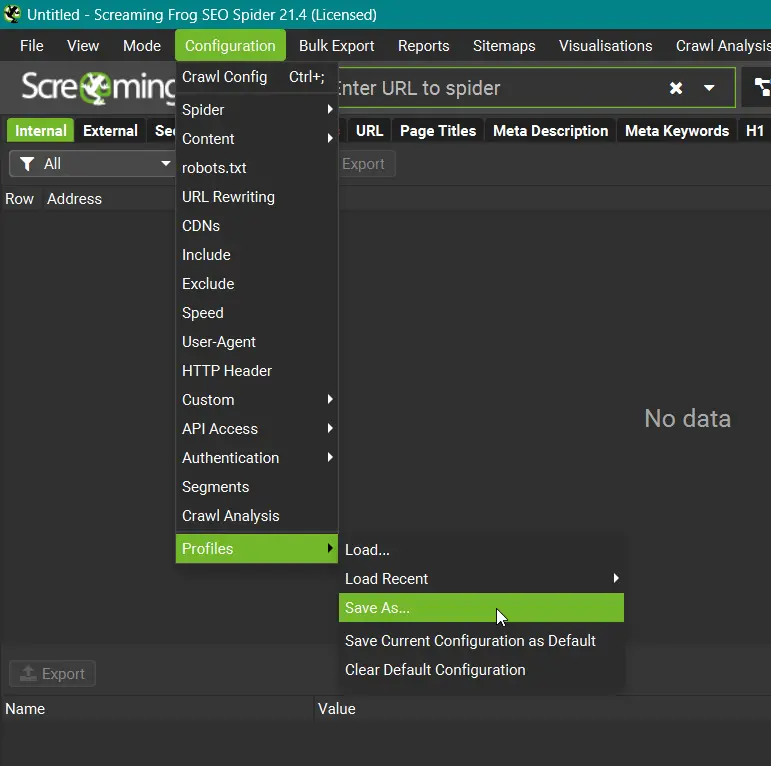
Empfehlung: Speichere deine Konfiguration ab!
Das kannst du tun, indem du im Konfigurationsmenü ganz unten unter “Profiles” deine Konfiguration speicherst. So kannst du sie künftig einfach laden und auch leicht mehrere Konfigurationen für verschiedene Fälle anlegen.
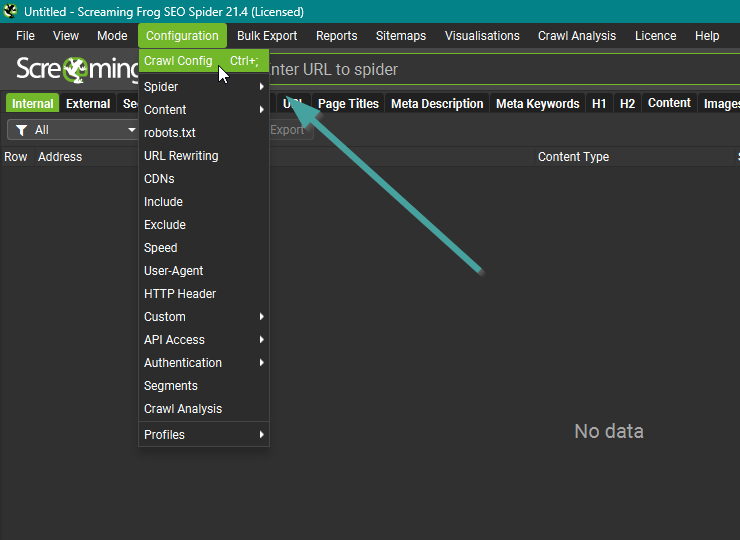
Storage Mode: RAM oder Festplatte?
Der Screaming Frog kann die erhobenen Daten entweder im RAM (Arbeitsspeicher) deines Rechners speichern, oder direkt auf eine Festplatte schreiben. Die Option findest du in den Einstellungen. Ich komme direkt zum praktischen Unterschied:
Memory Storage Mode
Wenn du kleine, schnelle Crawls machen möchtest, ist der Memory Storage Mode empfehlenswert. Solange du ausreichend RAM zugewiesen hast (unter Memory Allocation in den Einstellungen), sollte es hier keine Probleme geben.
Der Modus hat jedoch ein paar Nachteile gegenüber dem Database Storage Mode.
Database Storage Mode
Wenn deine Crawls größer sind, empfehle ich dir den Database Storage Mode. Nicht nur kannst du so Crawls in beliebiger Größe durchführen, zwei sehr wichtige Features des Screaming Frogs kannst du nur im Database Storage Mode nutzen:
- Segmentierung
- Crawl-Vergleiche
Empfehlung: Nutze direkt den Database Storage Mode, wenn du es ernst meinst.
Die 4 verschiedenen Crawl Modes
Der Screaming Frog verfügt über 4 verschiedene Modi:
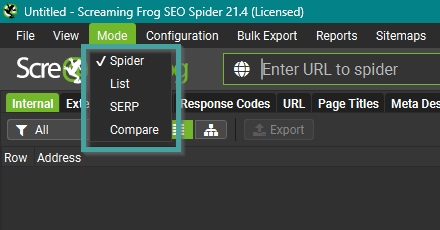
Spider
In diesem Modus crawled der Screaming Frog ausgehend von einer URL. Alle Ressourcen, die beim Crawl entdeckt werden, werden ebenfalls gecrawled. Dieses Verhalten kannst du auf gewisse Subdomains, Subfolder oder gar eine einzige URL eingrenzen. Dazu gibt es rechts neben der Eingabezeile ein Drop-Down-Menü, das dir diese Einstellung erlaubt.
In der Crawl-Konfiguration kannst du hierzu auch noch einige Feinheiten einstellen, wie die Tiefe des Crawls, die Beschränkung auf gewisse Formate (html, image, pdf, etc.).
In meinem kostenlosen Online Kurs „Screaming Frog für Einsteiger:innen“ gehe ich alle diese Einstellungen im Detail durch.
Da du wahrscheinlich meistens in diesem Modus arbeiten wirst, lohnt es sich, dich mit der Konfiguration vertraut zu machen. So stellst du sicher, dass du alle Daten erhebst, die du für deine Arbeit benötigst.
List
In diesem Modus crawled der Screaming Frog ausschließlich URLs einer von definierten Liste. Diese kannst du einfach reinkopieren, als Datei hochladen oder den Screamign Frog bitten, die Sitemap einer Domain abzufragen.
Dieser Modus ist gut geeignet, um gezielt eine Reihe von Seiten zu analysieren, ohne dabei jedes Mal die gesamte Webseite zu crawlen.
SERP
In diesem Modus kannst du vordefinierte Page Titles und Meta Descriptions in einer Datei hochladen. Der Screaming Frog gibt dir dann eine Vorschau einer SERP mit deinen eingegebenen Daten.
Ich muss gestehen, dass ich dafür andere Tools benutze, da es eigentlich nichts mit Webcrawling zu tun hat.
Compare
Dieser Modus erlaubt es dir, einen Crawl mit einem anderen zu vergleichen. Das kann sehr praktisch sein, wenn du deine Webseite über einen längeren Zeitraum wiederholt crawlst und deine Fortschritte sichtbar machen willst oder einfach eine Vergleichbarkeit des Webseitenzustands herstellen willst.
Wichtig: Dieser Modus steht dir nur im Database Storage Mode zur Verfügung!
Crawl-Konfiguration im Detail
Bevor wir uns die Konfiguration im Detail anschauen, frage dich zuerst: Was möchte ich eigentlich alles über meine Webseite wissen? Was ist das Ziel dieser Analyse?
Ausgehen davon wird es dir leichter fallen, Entscheidungen für oder gegen eine gewisse Konfiguration zu treffen. Doch warum solltest du dich hier überhaupt beschränken? Aus einem wichtigen Grund:
Je mehr du auswählst, desto langsamer wird der Crawl laufen. Das mag bei 100 URLs nicht sonderlich ins Gewicht fallen, willst du aber 10.000 URLs crawlen, kann das im Extremfall schon mal ein paar Stunden mehr oder weniger bedeuten. Bedenke das also, bevor du startest.
Hinweis: Ich gehe im Folgenden nicht auf jede Konfigurationsmöglichkeit ein, sondern auf die wichtigsten für den Anfang. Tiefer in die Materie gehe ich in meinem kostenlosen Online Kurs „Screaming Frog für Einsteiger:innen“.
Spider ➔ Crawl
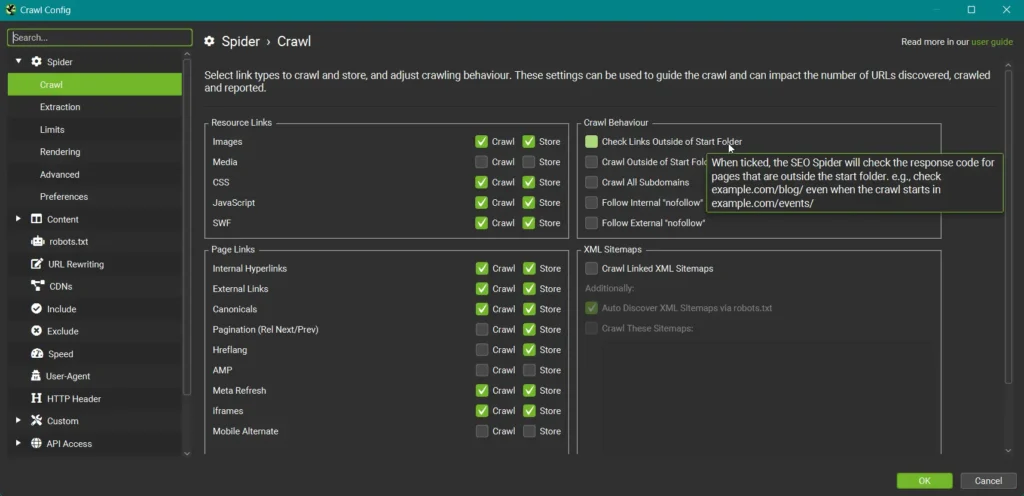
Im Bereich “Spider ➔ Crawl” kannst du dem Screaming Frog granulare Anweisungen geben. Die Standardeinstellungen siehst du im Bild. Frage dich, ob diese zu deiner Webseite passen und wähle entsprechend an oder ab.
Wenn du mit der Maus über die jeweilige Option hoverst, bekommst du eine Erklärung. Das hilft dir bei der Entscheidung.
Mache dir auch Gedanken darüber, ob du Meta Robots Anweisungen, wie “nofollow”, respektieren willst, oder nicht. Das kann nützlich sein, um das Verhalten eines Suchmaschinenbots nachzustellen.
Gibt es auf deiner Webseite verschiedene Subdomains, überlege dir, ob du alle davon crawlen willst, oder ob eine Eingrenzung hier genügt.
Meistens ist es ausreichend, den Screaming Frog die Sitemap selbst entdecken zu lassen. Doch wenn du einen Sitemap Index aufgrund mehrerer Sitemaps hast, kann es sich lohnen, hier einzugrenzen.
Auch hier gibt es keine perfekten Einstellungen, die auf jeden Anwendungsfall passen. Umso wichtiger, dass du deine Einstellungen selbst definierst und sie dann in der bereits erwähnten Config-Datei abspeicherst.
Spider ➔ Extraction
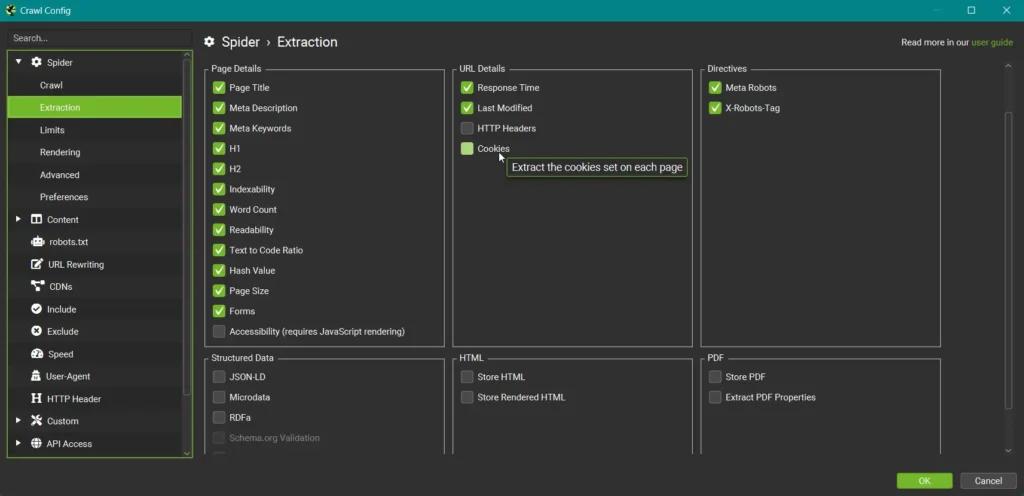
Im Bereich “Spider ➔ Extraction” kannst du definieren, welche Elemente einer Seite der Screaming Frog im Crawl speichern soll. Hierbei sind die Standardeinstellungen ebenfalls bereits sehr brauchbar, aber die folgenden Fragen kannst du dir dennoch stellen.
Verwendest du auf deiner Seite strukturierte Daten? Wenn ja, solltest du hier die Extraction anwählen, um zu prüfen, ob Probleme bestehen.
Benötigst du das HTML der URLs für deine Analysen? Du kannst es plain oder gerendert extrahieren. Bedenke hierbei nur, dass dein Crawl dabei schnell sehr groß werden kann.
Möchtest du PDFs deiner Webseite überprüfen? Auch hier gilt, dass es deinen Crawl schnell sehr groß werden lassen kann. Wenn es jedoch relevant für deine Webseite ist, dass PDFs einwandfrei zugänglich sind, hast du hier die Option, diese zu crawlen.
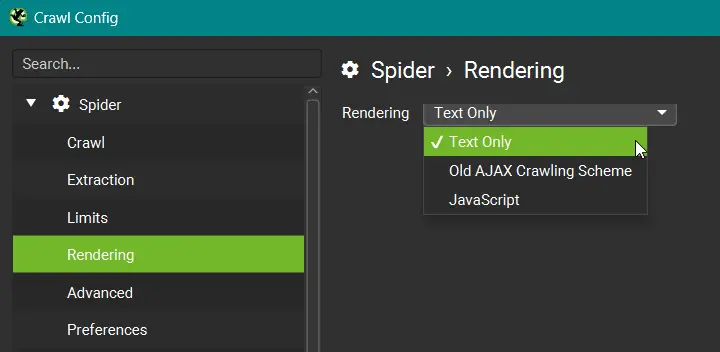
Spider ➔ Rendering
Der Bereich “Spider ➔ Rendering” ist wichtig, wenn deine Webseite für die korrekte Darstellung auf das Ausführen von JavaScript angewiesen ist. Wähle hierzu die Option “JavaScript” aus, damit der Screaming Frog dieses beim Crawlen auch rendert.
Solltest du das nicht tun, kann es sein, dass der Screaming Frog wichtige Elemente deiner Webseite nicht erfasst. In jedem Fall solltest du hier ein wenig testen, um Gewissheit zu haben, das auch alles gefunden wird, was du brauchst.
API Anbindungen
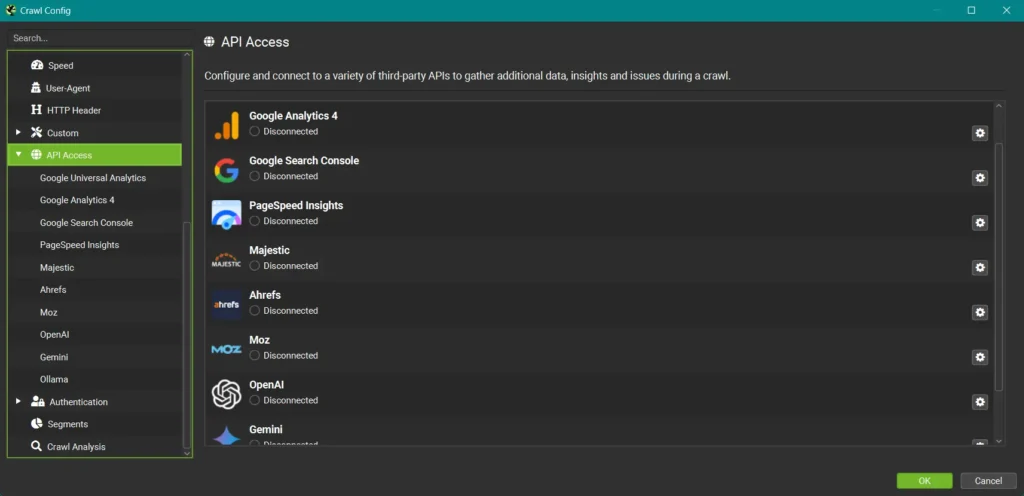
Du kannst deinen Crawl mit Daten anreichern, die du aus verschiedenen Quellen beziehen kannst. Dazu gehören Stand heute:
- Google Analytics 4
- Google Search Console
- PageSpeed Insights
- Majestic
- Ahrefs
- Moz
- OpenAI
- Gemini
- Ollama
Insbesondere die Daten aus der Google Search Console und Google Analytics 4 können deinen Crawl unglaublich aufwerten, denn so erhältst du zu jeder URL noch die entsprechenden Performance-Daten dazu.
Wichtig: In den Einstellungen der jeweiligen Tools musst du dich natürlich zunächst mit dem entsprechenden Google Account anmelden. Dann solltest du dir Gedanken zum Datumsbereich und weiteren Einstellungen machen, die du in den hier gezeigten Tabs (am Beispiel der Google Search Console) findest.
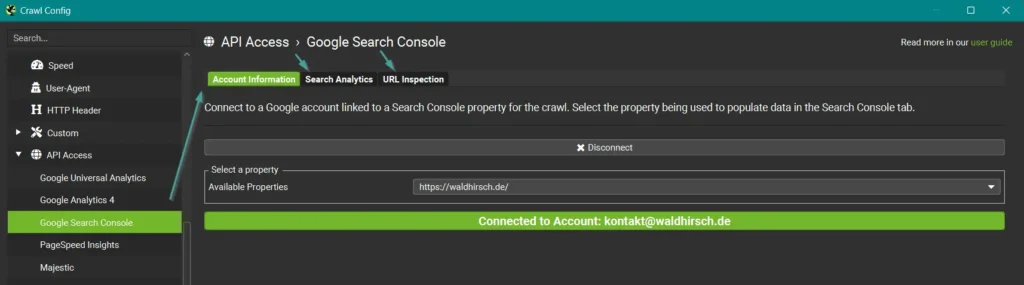
Natürlich kannst du auch alle anderen Integrationen nutzen, diese gehen jedoch meist mit einem kostenpflichtigen Account oder API Kontingent einher.
Für fortgeschrittene Analysen kann die Integration von KI unglaublich spannend sein, für Einsteiger würde ich jedoch zunächst empfehlen, sich auf das Wesentliche zu konzentrieren.
Segmentierung
Weiter oben habe ich bereits schon von Segmentierung gesprochen. Mit diesem Feature kannst du Bereiche deiner Webseite definieren (zum Beispiel über Verzeichnisse, es ist aber quasi alles möglich), denen du dann verschiedene Farben geben kannst. Diese farblichen Segmentierungen ziehen sich dann durch den kompletten Crawl und erlauben dir eine deutlich klarere Struktur in der Auswertung.
Wichtig: Diese Funktion steht dir nur im Database Storage Mode zur Verfügung.
Für den Anfang kannst du Segmente über wichtige URL-Verzeichnisse aufbauen. Wenn du später weitere Ideen hast, wie du deine Crawls einfärben willst, stehen dir beinahe grenzenlose Optionen zur Verfügung.
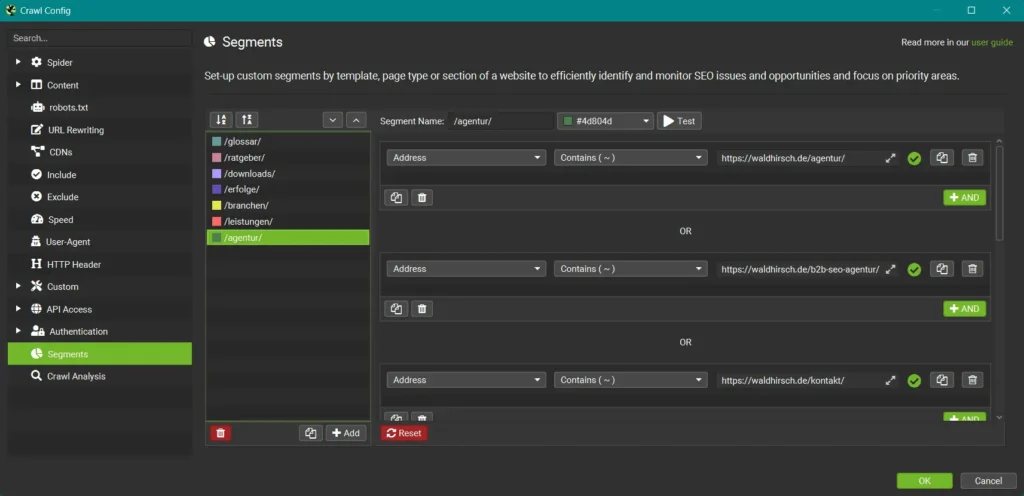
Wenn du dir später die Möglichkeiten der Visualisierungen mit dem Screaming Frog anschaust, wirst du ebenfalls von Segmentierung profitieren.
Konfiguration speichern
Du hast nun einige Konfigurationen vorgenommen, doch bedenke, dass die Konfiguration nicht permanent ist.
Damit deine Arbeit nicht verloren geht, wenn du den Screaming Frog schließt, speichere sie unbedingt ab.
Die Datei legst du am besten irgendwo sicher ab, du kannst sie dann über den selbst Dialog auch wieder laden.
Glückwunsch!
Du hast den Screaming Frog grundlegend konfiguriert!
Wenn du die praxisorientierte Anwendung und die vielen Features des Screaming Frogs in der Tiefe verstehe willst, empfehle ich dir meinen kostenlosen Online Kurs „Screaming Frog für Einsteiger:innen“.
Viel Spaß beim Crawlen! :)